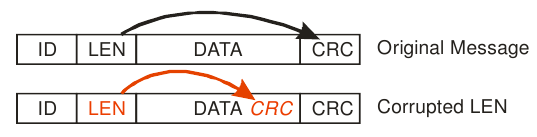
Figure 1. Corruption of message length field. Source: [Koopman], p. 30.
One of the challenges of digital preservation is the evaluation of data formats. It is important to choose well-designed data formats for general use. This article explains the reasons why the xz compressed data format is inadequate for most uses, including long-term archiving, data sharing, and free software distribution. The relevant weaknesses and design errors in the xz format are analyzed and, where applicable, compared with the corresponding behavior of the bzip2, gzip, and lzip formats. Key findings include: (1) safe interoperability between xz implementations is not guaranteed; (2) xz is vulnerable to unprotected flags and length fields; (3) LZMA2 is unsafe and less efficient than the original LZMA; (4) xz's extensibility is unreasonable and problematic; (5) xz includes useless features that increase the number of false positives for corruption; (6) xz shows inconsistent behavior with respect to trailing data; (7) error detection in xz is less accurate than in bzip2, gzip, and lzip.
Disclosure statement: The author is also author of the lzip format.
Acknowledgements: The author would like to thank Lasse Collin for his detailed and useful comments that helped improve the first version of this article. The author would also like to thank the fellow GNU developers who reviewed this article before publication and the people whose comments have helped to fill in the gaps.
This article was originally published under the title "Xz format inadequate for long-term archiving", but further analysis revealed that xz is significantly less safe than bzip2, gzip, and lzip for most uses.
This article tries to be as objective and complete as possible. Please report any errors or inaccuracies to the author at the lzip mailing list lzip-bug@nongnu.org or in private at antonio@gnu.org. As of today, no formal refutation of this article has been reported.
I gave desperate warnings against the obscurity, the complexity, and overambition of the new design, but my warnings went unheeded. I conclude that there are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies and the other way is to make it so complicated that there are no obvious deficiencies. The first method is far more difficult.
-- C.A.R. Hoare
I consider LZMA the best compression algorithm ever discovered. It is the culmination of the successful combination of Lempel-Ziv coding with entropy coding. When complemented with adequate integrity checking, LZMA is almost ideal for general-purpose compression and long-term archiving because of its simplicity, high compression ratio, acceptable decompression speed, accurate error detection, and inherent safety against corrupt compressed data. Sadly, its good qualities are being spoiled by embedding it in bad formats like lzma-alone, LZMA2, or xz. The main purpose of this article is to make clear that these bad formats need to be replaced with a format that enhances LZMA instead of wasting its qualities.
Both the xz compressed data format and its predecessor lzma-alone have serious design flaws. But while lzma-alone is a toy format lacking fundamental features, xz is a complex container format whose defects are not evident because they are hidden behind its (mis)features. For example, xz seems to be safer than other formats because it offers overkill check sequences like SHA-256. But behind this false appearance, xz fails to protect the length fields needed to decompress the data in the first place and sometimes fails to detect corruption. These defects increase the probability of data loss and of corruption going undetected, to the point of making xz inadequate for most uses, including long-term archiving, data sharing, and free software distribution. In retrospect, xz looks like an experimental format that somehow became widely used before anybody had the chance to check whether its features worked as advertised: [1] [2] [3] [4] [5] [6] [7].
This article analyzes the xz compressed data format, what is to mean the way bits are arranged in xz compressed files and the consequences of such arrangement. This article is about formats, not programs. In particular this article is not about bugs in any compression tool. The fact that the xz reference tool (xz-utils) has had more bugs than bzip2 and lzip combined is mainly a consequence of the complexity and poor design of the xz format. Also the uninformative error messages provided by the xz tool reflect the extreme difficulty of finding out what failed in case of corruption in a xz file.
The format used for distribution of source code should be chosen carefully because source tarballs are meant to be archived forever as a way to compile and run a given version of some software in the future, for example to decode old data. Bzip2, gzip, and lzip offer advantages over xz for long-term archiving. Lzip also offers better compression ratio than xz for the compression of source tarballs.
Compression may be good for long-term archiving. For compressible data, multiple compressed copies may provide redundancy in a more useful form and may have a better chance of surviving intact than one uncompressed copy using the same amount of storage space. This is especially true if the format provides recovery capabilities like those of lziprecover, which is able to find and combine the good parts of several damaged copies.
A lack of clarity in specification is one of the surest signs of a deficiency in the program it describes.
-- C.A.R. Hoare
On Unix-like systems, where a tool is supposed to do one thing and do it well, compressed file formats are usually formed by the compressed data, preceded by a header containing the parameters needed for decompression, and followed by a trailer containing integrity information. The file formats of bzip2, gzip, and lzip are designed this way, minimizing both overhead and false positives.
On the contrary, xz is a container format which currently contains another container format (LZMA2), which in turn contains a mix of LZMA data and uncompressed data. In spite of implementing just one compression algorithm, xz already manages 3 levels of headers, which increases its fragility. The xz file format is not even fully documented. The xz format specification describes only the container (i.e., the overhead), not the real compressed data. Section 3.2 of the xz format specification states that "the format of the filter-specific encoded data is out of scope of this document". The details about the [LZMA2 format] described in the Wikipedia were deduced from the source code of the xz-embedded decompressor included in the Linux kernel.
As a container format, xz is a fragmented format, meaning that xz implementations may choose what subset of the format they support. Fragmentation is normal in extensible container formats like xz. It is caused by optional filters and by unknown filters added in newer versions of the format. This type of fragmentation is not good for interoperability nor for long-term archiving, but is not a safety risk. A decoder that finds an unsupported filter type may just indicate that it can't decode the file, and then exit.
But xz has a second type of fragmentation caused by optional check types. This type of fragmentation is a defect of the xz format that may prevent decompressors from detecting corruption, and is analyzed in the next section.
The xz format has more overhead than bzip2, gzip, or lzip, most of it either not properly designed (e.g., unprotected headers) or plain useless (padding). In fact, a xz stream can contain such a large amount of overhead that the format designers deemed necessary to compress the overhead using unsafe methods.
There is no reason to use a container format for a general-purpose compressor. The right way of implementing a new compression algorithm is to provide a version number in the header, and the right way of implementing binary filters is to write a preprocessor that applies the filter to the data before feeding them to the compressor. (See for example mince).
The price of reliability is the pursuit of the utmost simplicity. It is a price which the very rich find most hard to pay.
-- C.A.R. Hoare
Integrity checking in xz offers multiple choices of check types, all of them optional except CRC32 which is recommended (i.e., not required). (See [Xz format], section 2.1.1.2 'Stream Flags'. See also [RFC 2119] for the definitions of 'optional' and 'recommended'). Safe interoperability between xz implementations is not guaranteed. For example, xz-utils produces by default files with an optional check type (CRC64), while the xz-embedded decompressor does not support the optional check types.
Offering multiple optional check types is a defect of the xz format that, instead of increasing safety, prevents a xz decompressor from checking the integrity of a file with a check type not supported by that decompressor, allowing corruption to remain undetected even when the file provides a check sequence. It also introduces a point of failure in the xz stream; if the corruption affects the 'Stream Flags', the decompressor won't be able to check the integrity of the data because the type and size of the check sequence are lost.
Extensibility of check types is a risk for the future. Even if one uses a xz decompressor that supports all the check types defined today, a new check type may be defined at any moment, rendering current decompressors unsafe; the decompressor will be able to decompress the data but will be unable to check their integrity. It may also be impossible to retrofit support for the new check type into some of the decompressors already deployed.
Bzip2, gzip, and lzip are free from these defects; they always check the integrity of the decompressed data. Moreover, multiple check types are unnecessary. [Safety of the lzip format] shows that a LZMA decoder combined with a CRC32 provides more than enough safety reliably.
You can never solve a problem on the level on which it was created.
-- Albert Einstein
The best way to prevent problems caused by unnecessary features like padding bytes or multiple optional check types is to not use them. This is what bzip2, gzip, and lzip do. Instead of this, xz defines several useless fields and then protects them with CRCs, increasing the probability of data loss twice. For example, it is obvious that the whole integrity checking of xz, including the 'Stream Flags' and their protection, was designed by someone without a clue about how to use a CRC or even about how to protect a dataword.
As a result, xz refuses to decompress an undamaged compressed payload if it finds errors in parts of the compressed file that do not affect decompression (for example in padding bytes), causing unnecessary data loss. The xz format specification does not guarantee that the integrity of the decompressed data will be checked, but it mandates that the decompression must be aborted as soon as a damaged padding byte is found. (See sections 2.2, 3.1.6, 3.3, and 4.4 of [Xz format]). Xz goes so far as to "protect" padding bytes with a CRC32.
Mandatory integrity checking of the decompressed data is the only way to guarantee the integrity of the decompressed data. Verifying the compressed file with a cryptographic signature does not protect against memory errors nor against undetected bugs in the decompressor or in the system libraries, and therefore does not guarantee the integrity of the decompressed data.
The only reason to be concerned about the integrity of the compressed file itself is to be sure that it has not been modified or replaced with other file. But no amount of checking in the decompressor can guarantee that a file has not been modified or replaced. Some other means must be used for this purpose, for example an external cryptographically secure hash of the file.
Our main failure was overambition.
-- C.A.R. Hoare
The design of the xz format is based on two false ideas: that better compression algorithms can be mass-produced like cars in a factory, and that it is practical to embed all these algorithms in one format. Note, for example, that some xz implementations already do not even fully support integrity checking, and at least one implementation does not support integrity checking at all.
Xz has room for 2^63 filters, which can then be combined to make an even larger number of algorithms. Xz reserves less than 0.8% of filter IDs for custom filters, but even this small range provides about 8 million custom filter IDs for each human inhabitant on earth. There is not the slightest justification for such egregious level of extensibility. Every useless choice allowed by a format takes space and makes corruption both more probable and more difficult to recover from.
The basic ideas of compression algorithms were discovered early in the history of computer science. LZMA is based on ideas discovered in the 1970s. Don't expect an algorithm much better than LZMA to appear anytime soon, much less several of them in a row.
In 2008 one of the designers of xz (Lasse Collin) warned me that lzip would become stuck with LZMA while others moved to LZMA2, LZMA3, LZMH, and other algorithms. Now xz-utils is usually unable to match the compression ratio of lzip because LZMA2 has more overhead than LZMA and, as expected, no new algorithms have been added to xz-utils.
The xz format lacks a version number field. The only reliable way of knowing whether a given version of a xz decompressor can decompress a given file is by trial and error. The 'file' utility does not provide any help (note that no version information is shown for xz):
$ file COPYING.* COPYING.lz: lzip compressed data, version: 1 COPYING.xz: XZ compressed data
Xz-utils can report the minimum version of xz-utils required to decompress a given file, but it must decode each block header in the file to find it out, and only can report older versions of xz-utils by using its knowledge of the features implemented in each past version of itself. If a newer version of xz-utils is required, the file says nothing about which one it may be. The report from xz-utils does not help either to find out what version of other decompressors (for example 7-zip) could decompress the file. Note that the version of xz-utils reported may be unable to decompress the file if it was built without support for some feature present in the file.
The extensibility of bzip2 and lzip is better. Both formats provide a version field. Therefore it is trivial for them to seamlessly and reliably incorporate a new compression algorithm because any tool knows the format version of any file. Newer tools know what algorithm to use and old tools can report to the user the format version required to decompress a newer file, from which it is easy to find out the version of a tool able to decompress the file. If an algorithm much better than LZMA is found, a version 2 lzip format (perfectly fit to the new algorithm) can be designed, along with a version 2 lzip tool able to decompress the old and new formats transparently. Bzip2 is already a 'version 2' format. The reason why bzip2 does not decompress bzip files is that the original bzip format was abandoned because of problems with software patents.
The extensibility of gzip is obsolete mainly because of the 32-bit uncompressed size (ISIZE) field.
In any respectable branch of engineering, failure to observe such elementary precautions would have long been against the law.
-- C.A.R. Hoare
According to [Koopman] (p. 50), one of the "Seven Deadly Sins" (i.e., bad ideas) of CRC and checksum use is failing to protect a message length field. This causes vulnerabilities due to framing errors. Note that the effects of a framing error in a data stream are more serious than what Figure 1 suggests. Not only data at a random position are interpreted as the CRC. Whatever data that follow the bogus CRC will be interpreted as the beginning of the following field, preventing the successful decoding of any remaining data in the stream.
Figure 1. Corruption of message length field.
Source: [Koopman], p. 30.
Except the 'Backward Size' field in the stream footer, none of the many length fields in the xz format is protected by a check sequence of any kind. Not even a parity bit. All of them suffer from the framing vulnerability illustrated in the picture above. In particular every LZMA2 header contains one 16-bit unprotected length field. Some length fields in the xz format are of variable size themselves, adding a new failure mode to xz not found in the other three formats; double framing error.
Bzip2 is affected by this defect to a lesser extent; it contains two unprotected length fields in each block header. Gzip may be considered free from this defect because its only top-level unprotected length field (XLEN) can be validated using the LEN fields in the extra subfields. Lzip is free from this defect.
Optional fields are just as unsafe as unprotected length fields if the flag that indicates the presence of the optional field is itself unprotected. The result is the same; framing errors. Again, except the 'Stream Flags' field, none of those flags in the xz format is protected by a check sequence. In particular the critically important 'Block Flags' field in block headers and bit 6 in the control byte of the numerous LZMA2 headers are not protected.
Bzip2 contains 16 unprotected flags for optional huffman bitmaps in each block header. Gzip just contains one byte with four unprotected flags for optional fields in its header. Lzip is free from optional fields.
By documenting a design, the designer exposes himself to the criticisms of everyone, and he must be able to defend everything he writes.
-- John Cosgrove, quoted by Fred Brooks
Xz stores many (potentially large) numbers using a variable-length representation terminated by a byte with the most significant bit (msb) cleared. In case of corruption, not only the value of the field may become incorrect, the size of the field may also change, causing a framing error in the following fields. Xz uses such variable-length integers to store the size of other fields. In case of corruption in the size field, both the position and the size of the target field may become incorrect, causing a double framing error. See for example [Xz format], section 3.1.5 'Size of Properties' in 'List of Filter Flags'. Bzip2, gzip, and lzip store all fields representing numbers in a safe fixed-length representation.
Xz features a monolithic index that is especially vulnerable to cascading framing errors. Some design errors of the xz index are:
If only we could learn the right lessons from the successes of the past, we would not need to learn from our failures.
-- C.A.R. Hoare
The xz-utils manual says that LZMA2 is an updated version of LZMA to fix some practical issues of LZMA. This wording suggests that LZMA2 is some sort of improved LZMA algorithm. (After all, the 'A' in LZMA stands for 'algorithm'). But LZMA2 is a container format that divides LZMA data into chunks in an unsafe way.
The [LZMA2 format] contains an unrestricted mix of LZMA chunks and uncompressed data chunks. Each chunk starts with a header that is not protected by any check sequence in spite of containing the type and size of the following data. Therefore, every bit flip in a LZMA2 header causes either a framing error or a desynchronization of the decoder. In any case it is usually not possible to decode the remaining data in the block or even to know what failed. Compare this with [Deflate], which protects the length field of its non-compressed blocks. (Deflate's compressed blocks do not have a length field).
Note that of the 3 levels of headers in a xz file (stream, block, LZMA2), the most numerous LZMA2 headers are the ones not protected by a check sequence. There is usually one stream header and one block header in a xz file, but there is at least one LZMA2 header for every 64 KiB of LZMA2 data in the file. In extreme cases the LZMA2 headers can make up to a 3% of the size of the file:
-rw-r--r-- 1 14208 Oct 21 17:26 100MBzeros.lz -rw-r--r-- 1 14195 Oct 21 17:26 100MBzeros.lzma -rw-r--r-- 1 14676 Oct 21 17:26 100MBzeros.xz
The files above were produced by lzip (.lz) and xz-utils (.lzma, .xz). The LZMA stream is identical in the .lz and .lzma files above; they just differ in the header and trailer. The .xz file is larger than the other two mainly because of the 50 LZMA2 headers it contains. LZMA2 headers make xz both more fragile and less efficient.
In practice, for compressible data, LZMA2 is just LZMA with 0.015%-3% more overhead. The maximum compression ratio of LZMA is about 7089:1, but LZMA2 is limited to 6875:1 approximately (measured with 1 TB of data). For uncompressible data, xz expands the data less than lzip (0.01% vs 1.4%), but at the cost of making it more vulnerable to undetected corruption because xz stores uncompressible data uncompressed, and corruption in the uncompressed chunks of a LZMA2 stream can't be detected by the decoder, leaving the (optional) check sequence as the only way of detecting errors there.
On the other hand, the original LZMA data stream provides embedded error detection. Any distance larger than the dictionary size acts as a forbidden symbol, allowing the decoder to detect the approximate position of most errors, and leaving little work for the check sequence in the detection of errors. LZMA2 inserts headers that interrupt the decoding of the LZMA stream and interfere with the ability of the LZMA decoder to detect the approximate position of errors. If any of the (unprotected) size fields in one of those headers gets corrupt, the error is incorrectly detected far from its real position.
LZMA2 chunks provide similar functionality to Deflate blocks, but are less safe and less efficient. LZMA2 could have been safer and more efficient if only its designers had copied the structure of Deflate; terminate compressed blocks with a marker, and protect the length of uncompressed blocks. This would have reduced the overhead, and therefore the number of false positives, in the files above by a factor of 25. For compressible files, that only need a header and a marker, the improvement is usually of 8 times less overhead per mebibyte of compressed size (about 500 times less overhead for a file of 64 MiB).
Section 5.3.1 of the xz format specification states that LZMA2 "improves support for multithreading", but in practice LZMA2 is not suitable for parallel decompression mainly for two reasons:
The general tendency is to over-design the second system, using all the ideas and frills that were cautiously sidetracked on the first one. The result, as Ovid says, is a "big pile".
-- Fred Brooks
Multithreading support is probably the area of the xz format specification where the lack of conceptual integrity and the second-system effect are more evident. While the lzma-alone format does not provide any support for multithreading, the xz format provides 3 types of support for multithreading: LZMA2, blocks, and streams. The 3 types are placed at different levels in the format, and can be used simultaneously; a xz file may contain several streams (multistream), each stream may contain several blocks (multiblock), and each block may contain several LZMA2 dictionary resets.
Because of design errors, none of the 3 types by itself, nor any combination of them, provides reliable multithreading support in xz. Moreover, by defining more than one way of doing the same thing, xz opens the door to incompatibilities between tools. A tool that creates multiblock files may be unable to decompress multistream files in parallel, and vice versa. (This has happened in practice).
LZMA2 is only suitable for parallel compression (as long as SHA-256 is not used), but not for efficient parallel decompression. Therefore, the three types of parallel-decompressible xz files are multiblock, multistream, and a combination of the two (obtained, for example, by concatenating two or more multiblock files).
As a xz file consists of one or more xz streams (see [Xz format], section 2 'Overall Structure of .xz File'), multistream xz files (without padding between streams) are the natural choice for supporting multithreaded decompression. Xz could have provided efficient parallel compression and decompression by using multiple streams, without resorting to blocks nor to dictionary resets. But the xz format specification just recommends (i.e., does not require) support for multistream files. A xz decompressor is allowed to stop after the first stream and discard the rest of the file. (This also has happened in practice).
This leaves multiblock-single-stream files as the only type of file that a) is guaranteed to be fully decompressed by a compliant decompressor and b) can be efficiently compressed and decompressed in parallel. Unfortunately, all the blocks in a xz stream share a common index (see [Xz format], section 2.1 'Stream') which has several design errors.
Bzip2 files can be decompressed in parallel because the beginning of each block is marked with a 6-byte string. Gzip files can't be decompressed in parallel. Lzip supports efficient parallel compression and decompression by means of multimember files (equivalent to multistream files in xz).
Xz is the only format of the four considered here whose parts are aligned to a multiple of four bytes. The size of a xz file must also be a multiple of four bytes. To achieve this, xz includes padding everywhere: after headers, blocks, the index, and the whole stream. If the padding is altered in any way, "the decoder MUST indicate an error" according to the xz format specification.
Neither gzip nor lzip include any padding. Bzip2 includes a minimal amount of padding (at most 7 bits) at the end of the whole stream, but it ignores any corruption in the padding.
Xz justifies alignment as being perhaps able to increase speed and compression ratio (see [Xz format], section 5.1 'Alignment'), but such increases can't happen because:
One additional problem of the xz alignment is that four bytes are not enough; the IA64 filter has an alignment of 16 bytes. Alignment is a property of each filter that can only be managed by the archiver, not a property of the whole compressed stream. Even the xz format specification acknowledges that alignment of input data is the job of the archiver, not of the compressor.
The conclusion is that the 4-byte alignment is a misfeature that wastes space, increases the number of false positives for corruption, and worsens the burst error detection in the stream footer without producing any benefit at all.
The xz format specification forbids appending data to a file, except what it defines as 'stream padding'. Defining stream padding makes xz show inconsistent behavior with respect to trailing data. Xz accepts the addition of any multiple of 4 null bytes to a file. But if the number of null bytes appended is not a multiple of 4, or if any of the bytes is non-null, then the decoder must indicate an error.
A format specification that forces the decompressor to report as corrupt the only surviving copy of an important file just because cp had a glitch and appended some garbage at the end of the file is unsafe. The worst thing is that the xz format specification does not offer any compliant way of ignoring such trailing garbage. Once a xz file gets any trailing garbage appended, it must be manually removed to make the file compliant again.
In a vain attempt to avoid such inconsistent behavior, xz-utils provides the option '--single-stream', which is just plain wrong for multistream files because it makes the decompressor ignore everything beyond the first stream, discarding any remaining valid streams and silently truncating the decompressed data:
cat file1.xz file2.xz file3.sig > file.xz xz -d file.xz # indicates an error xz -d --single-stream file.xz # causes silent data loss xz -kd --single-stream file.xz # causes silent truncation
The '--single-stream' option violates the xz format specification which requires the decoder to indicate an error if the stream padding does not meet its requirements. The xz format should provide a compliant way to ignore any trailing data after the last stream, just like bzip2, gzip, and lzip do by default.
The following sections use statistics to analyze the inaccuracy of xz in the detection of errors, a minor defect compared with other defects of xz. Some people find these sections boring, so you may want to skip them.
"There can be safety tradeoffs with the addition of an error-detection scheme. As with almost all fault tolerance mechanisms, there is a tradeoff between availability and integrity. That is, techniques that increase integrity tend to reduce availability and vice versa. Employing error detection by adding a check sequence to a dataword increases integrity, but decreases availability. The decrease in availability happens through false-positive detections. These failures preclude the use of some data that otherwise would not have been rejected had it not been for the addition of error-detection coding". ([Koopman], p. 33).
But the tradeoff between availability and integrity is different for data transmission than for data archiving. When transmitting data, usually the most important consideration is to avoid undetected errors (false negatives for corruption), because a retransmission can be requested if an error is detected. Archiving, on the other hand, usually implies that if a file is reported as corrupt, "retransmission" is not possible. Obtaining another copy of the file may be difficult or impossible. Therefore accuracy (freedom from mistakes) in the detection of errors becomes the most important consideration.
Two error models have been used to measure the accuracy in the detection of errors. The first model consists of one or more random bit flips affecting just one byte in the compressed file. The second model consists of zeroed 512-byte blocks aligned to a 512-byte boundary, simulating a whole sector I/O error. Just one zeroed block per trial. The first model is considered the most important because bit flips in the compressed data are the most difficult to detect and they happen even in the most expensive hardware [MSL].
Integrity checking in compressed files is different from other cases (like Ethernet packets) because the data that can become corrupted are the compressed data, but the data that are checked (the dataword) are the decompressed data. Decompression can cause error multiplication; even a single-bit error in the compressed data may produce any random number of errors in the decompressed data, or even modify the size of the decompressed data.
In the cases where the decompression causes error multiplication, the error model seen by the check sequence is one of unconstrained random data corruption. (Remember that the check sequence checks the integrity of the decompressed data). This means that the choice of error-detection code (CRC or hash) is largely irrelevant, and that the probability of an error being undetected by the check sequence (Pudc) is 1 / (2^n) for a check sequence of n bits. (See [Koopman], p. 5). But in the cases where an error does not cause error multiplication, a CRC is preferable to a hash of the same size because of the burst error detection capabilities of the CRC which guarantee the detection of small errors.
Decompression algorithms are usually able to detect some errors in the compressed data (for example a backreference to a point before the beginning of the data). Therefore, if the errors not detected by the decoder are not "special" for the check sequence (neither guaranteed to be caught nor guaranteed to be missed), then the total probability of an undetected error (Pud) is the product of the probability of the error being undetected by the decoder (Pudd) and the probability of the error being undetected by the check sequence (Pudc): Pud = Pudd * Pudc
It is also possible that a small error in the compressed data does not alter at all the decompressed data. Therefore, for maximum availability, only the decompressed data should be tested for errors. Testing the compressed data beyond what is needed to perform the decompression increases the number of false positives without usually reducing the number of undetected errors.
Of course, error multiplication was not applied in the analysis of fields that are not compressed, for example 'Block Header'. Burst error detection was also considered for the 'Stream Flags' and 'Stream Footer' fields.
Trial decompressions were performed using the 'unzcrash' tool included in the lziprecover package.
The following sections describe the places in the xz format where error detection suffers from low accuracy and explain the cause of the inaccuracy in each case.
Many poor systems come from an attempt to salvage a bad basic design and patch it with all kinds of cosmetic relief.
-- Fred Brooks
A well-known property of CRCs is their ability to detect burst errors up to the size of the CRC itself. Using a CRC larger than the dataword is an error because a CRC just as large as the dataword equally detects all errors while it produces a lower number of false positives.
In spite of the mathematical property described above, the 16-bit 'Stream Flags' field in the xz stream header is protected by a CRC32 twice as large as the field itself, providing an unreliable error detection where 2 of every 3 errors reported is a false positive. The inaccuracy reaches 67%. CRC16 is a better choice from any point of view. It can still detect all errors in 'Stream Flags', but produces half the false positives as CRC32.
Moreover, knowing the properties of CRCs is not required to avoid the error above because a 100% redundancy is enough to detect all the errors in the dataword. See for example Deflate, which protects the length field of its non-compressed blocks by using a complemented copy of the length field itself. There is no justification for the 200% redundancy used by xz.
Note that a copy of the 'Stream Flags', also protected by a CRC32, is stored in the stream footer. With such amount of redundancy xz should be able to repair a fully corrupted 'Stream Flags'. Instead of this the format specifies that if one of the copies, or one of the CRCs, or the backward size in the stream footer gets any damage, the decoder must indicate an error. The result is that getting a false positive for corruption related to the 'Stream Flags' is 7 times more probable than getting real corruption in the 'Stream Flags' themselves.
The 'Stream Footer' field contains the rounded-up size of the index field and a copy of the 'Stream Flags' field from the stream header, both protected by a CRC32. The inaccuracy of the error detection for this field reaches a 40%; 2 of every 5 errors reported is a false positive.
The CRC32 in 'Stream Footer' provides a reduced burst error detection because it is stored at front instead of back of codeword. (See [Koopman], p. C-20). Testing has found several undetected burst errors of 31 bits in this field, while a CRC32 correctly placed would have detected all burst errors up to 32 bits. The reason adduced by the xz format specification for this misplacement is to keep the four-byte fields aligned to a multiple of four bytes, but the 4-byte alignment is unjustified.
The 'Block Header' is of variable size, ranging from 8 to 1024 bytes in multiples of four bytes. Therefore the inaccuracy of the error detection varies between 0.4% and 58%, being usually of a 58% (7 of every 12 errors reported are false positives). As shown in the graph below, CRC16 would have been a more accurate choice for any size of 'Block Header'.
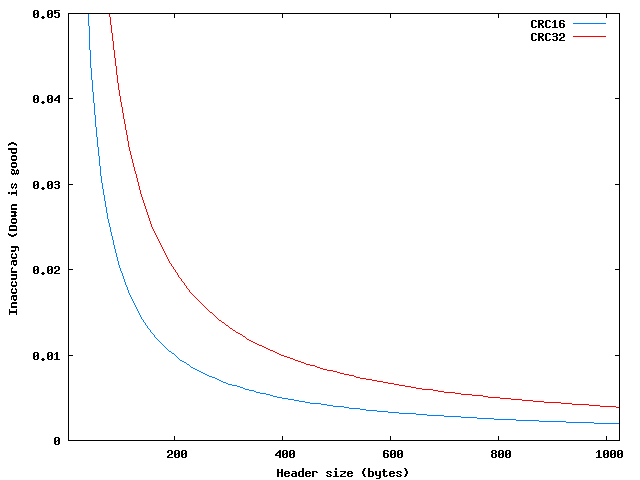
Figure 2. Inaccuracy of block header CRC for all possible header sizes.
Xz specifies several types of check sequences (CS) for the decompressed data: none, CRC32, CRC64, and SHA-256. Each check sequence provides better accuracy than the next larger one up to a certain compressed size. For the single-byte error model, the inaccuracy for each compressed size and CS size is calculated by the following formula (all sizes in bytes):
Inaccuracy = (compressed_size * Pudc + CS_size) / (compressed_size + CS_size)
Applying the formula above, it results that CRC32 provides more accurate error detection than CRC64 up to a compressed size of about 16 GiB, and more accurate than SHA-256 up to 112 GiB. It should be noted that SHA-256 provides worse accuracy than CRC64 for all possible block sizes.
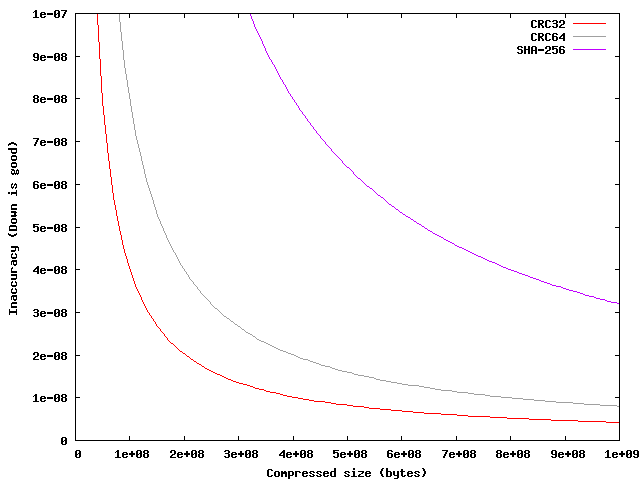
Figure 3. Inaccuracy of block check up to 1 GB of compressed size.
For the zeroed-block error model, the inaccuracy curves are similar to the ones in figure 3, except that they have discontinuities because a false positive can be produced only if the last block is suitably aligned.
The results above assume that the decoder does not detect any errors, but testing shows that, on large enough files, the Pudd of a pure LZMA decoder like the one in lzip is of about 2.52e-7 for the single-byte error model. More precisely, 277.24 million trial decompressions on files ranging from 1 kB to 217 MB of compressed size resulted in 70 errors undetected by the decoder (all of them detected by the CRC). This additional detection capability reduces the Pud by the same factor. (In fact the reduction of Pud is larger because 9 of the 70 errors didn't cause error multiplication; they produced just one wrong byte in the decompressed data, which is guaranteed to be detected by the CRC). The estimated Pud for lzip, based on these data, is of about 2.52e-7 * 2.33e-10 = 5.88e-17.
For the zeroed-block error model, the additional detection capability of a pure LZMA decoder is probably much larger. A LZMA stream is a check sequence in itself, and large errors seem less probable to escape detection than small ones. In fact, the lzip decoder detected the error in all the 2 million trial decompressions run with a zeroed-block. The xz decoder can't achieve such performance because LZMA2 includes uncompressed chunks, where the decoder can't detect any errors.
There is a good reason why bzip2, gzip, lzip, and most other compressed formats use a 32-bit check sequence; it provides for an optimal detection of errors. Larger check sequences may (or may not) reduce the number of false negatives at the cost of always increasing the number of false positives. But significantly reducing the number of false negatives may be impossible if the number of false negatives is already insignificant, as is the case in bzip2, gzip, and lzip files. On the other hand, the number of false positives increases linearly with the size of the check sequence. CRC64 doubles the number of false positives of CRC32, and SHA-256 produces 8 times more false positives than CRC32, decreasing the accuracy of the error detection instead of increasing it.
File corruption is an unlikely event. Being unable to restore a file because the backup copy is also damaged is even less likely. But unlikely events happen constantly to somebody somewhere. This is why tools like GNU ddrescue, bzip2recover, and lziprecover exist in the first place. Lziprecover defines itself as "a last line of defense for the case where the backups are also damaged".
The safer a format is, the easier it is to develop a capable recovery tool for it. Neither xz nor gzip do provide any recovery tool. Bzip2 provides bzip2recover, which can help to manually assemble a correct file from the undamaged blocks of two or more copies. Lzip provides lziprecover, which can produce a correct file by merging the good parts of two or more damaged copies, can repair slightly damaged files without the need of a backup copy, and implements Forward Error Correction with extra recovery capabilities for lzip files.
For a successful technology, reality must take precedence over public relations, for nature cannot be fooled.
-- Richard P. Feynman
Most free software projects using xz (for example to compress their source tarballs), probably chose it because LZMA compresses better than gzip and bzip2, and because the developers of those projects didn't know about the defects of xz, or about lzip, when they adopted xz. Evaluating formats is difficult. Therefore free software projects tend to use the most advertised formats. Both lzma-alone and xz have gained some popularity in spite of their defects mainly because they are associated to popular projects like GNU Coreutils or the 7-zip archiver. (As far as I know, the main cause of the popularity of xz among GNU/Linux distributions was the early adoption of lzma-alone and xz by GNU Coreutils when xz was still in alpha status).
By now there is ample evidence that xz is not a good format. But xz is widely deployed and it will take time for enough people to overcome the groupthink that allowed its initial adoption. I hope this article can inspire developers to improve the digital infrastructure of society by choosing safer basic formats and tools.
To have our best advice ignored is the common fate of all who take on the role of consultant, ever since Cassandra pointed out the dangers of bringing a wooden horse within the walls of Troy.
-- C.A.R. Hoare
There are several reasons why the xz compressed data format is inadequate for general use. To begin with, xz is a complex container format that is not even fully documented and is inadequate for long-term archiving, especially of valuable data. Using a complex format for long-term archiving would be a bad idea even if the format were well-designed, which xz is not. In general, the more complex the format, the less probable that it can be decoded in the future by a digital archaeologist. For long-term archiving, simple is robust.
The xz format specification does not guarantee safe interoperability between implementations because it offers multiple optional check types. A xz decompressor may fail to detect corruption even when the file provides a check sequence. A xz decompressor may also stop after the first stream and discard the rest of the file. These defects make xz inadequate for most uses, including long-term archiving, data sharing, and free software distribution.
Xz is unreasonably extensible; it has room for trillions of compression algorithms, but currently only provides one, LZMA2, which in spite of its name is not an improved version of LZMA, but an unsafe container for LZMA data. Such egregious level of extensibility makes corruption both more probable and more difficult to recover from. Additionally, the xz format lacks a version number field, which makes xz's extensibility problematic.
Xz fails to protect critical fields like length fields and flags signaling the presence of optional fields. Xz uses variable-length integers unsafely, especially when they are used to store the size of other fields or when they are concatenated together. These defects make xz fragile, meaning that most of the times when it reports a false positive, the decoder state is so mangled that it is unable to recover the decompressed data.
Error detection in the xz format is less accurate than in bzip2, gzip, and lzip formats mainly because of false positives, and especially if an overkill check sequence like SHA-256 is used in xz. Another cause of false positives is that xz tries to detect errors in parts of the compressed file that do not affect decompression, like the padding added to keep the useless 4-byte alignment. In total xz reports several times more false positives than bzip2, gzip, or lzip, and every false positive may result in unnecessary loss of data.
All these defects and design errors reduce the value of xz as a general-purpose format because anybody wanting to archive a file already compressed in xz format will have to either leave it as-is and face a larger risk of losing the data, or waste time recompressing the data into a format more suitable for long-term archiving.
The weird combination of unprotected critical fields, multiple optional check types, and padding bytes "protected" by a CRC32 can only be explained by the inexperience of the designers of xz. It is said that given enough eyeballs, all bugs are shallow. But the adoption of xz by several GNU/Linux distributions shows that if those eyeballs lack the required experience, it may take too long for them to find the bugs. It would be an improvement for data safety if compressed data formats intended for broad use were designed by experts and peer reviewed before publication. This would help to avoid design errors like those of xz, which are difficult to fix once a format is in use.
The lzip format specification has been reviewed by many people along the years and is believed to be free from design errors. Therefore, my advice is that lzip should be used instead of xz, except perhaps for the compression of short-lived executables, for which zstd may be preferable because of its faster decompression speed.
Copyright © 2016-2026 Antonio Diaz Diaz.
You are free to copy and distribute this article without limitation, but you are not allowed to modify it.
First published: 2016-06-11
Updated: 2026-04-24
This page does not use javascript.